多年前,又是周六客服打电话过来,平台官网不能访问,app完全无法打开,客户在QQ群和微信群中各种反馈,说平台是不是跑路了?客服的多条400热线完全被打爆,电话已经接不过来…
前言
一直以来总是想以什么方式去记录下自己在互金行业的这段经历,趁着自己还记得清楚,还能找到一些资料原型,一方面可以分享出来供大家参考,但是更重要就是多年以后我可以根据这些文章回忆起来自己的那段激情岁月。
想了很久但一直没有实施,后来觉得应该从架构的角度来梳理一篇文章,就写了《从零到百亿互联网金融架构发展史》这篇文章;最后认为只有实战出来的东西以及解决问题的过程,才是工作中最宝贵的经验,应该把它分享出来,在梳理的过程中有三起事故和黑客攻击事件比较有代表性,就整理出了下面这四篇文章,本篇文章从整体来回忆一下一路走过来所经历过的救火故事。
作为一个互联网金融平台,涉及到用户资金,任何的服务(资金)差错用户都是不可容忍的,用户不懂什么是数据库,不知道什么网络不通,就是一会看不到钱在app里面展示都会觉得不安。在已经有很多P2P公司跑路的前提下,用户个个已经被锻炼成为福尔摩斯侦探,每天打开app查看收益,监控着平台一切,甚至半夜升级断网十分钟,也会被用户察觉,直接就发到群里面,更有甚者直接在QQ群或者微信群中说你们的技术行不行!
我们常说的互联网工作经验,一方面是开发经验,但其实更重要的是处理问题的能力。那么处理问题的能力怎么来呢,就是不断的去解决问题,不断的去总结经验,其中处理生产环境中问题的经验更甚,因为在处理生产环境中对个人的压力和临危应变的能力要求最高,你不但需要面临千万个用户反馈,客服不时得催促而且旁边可能就站了N个领导在看着你,一副你行不行的样子要求立刻马上解决问题!这个时候你的操作就非常重要,稍有不慎便会引发二次生产事故。
说了这么多,只是想说明,生产事故对技术综合能力要求颇高,更是锻炼处理问题能力最佳时机!下面给大家介绍我们从零开发到现在百亿交易量所遇到的几次关键事故,有大有小挑出一些比较有代表性的事件来分享。
并发满标
公司系统刚上线的时候,其实没有经历过什么大量用户并发的考验,结果公司做了一个大的推广,涌入了一批用户来抢标,共1000万的标的几乎都在10秒之内搞定,大概会有上万左右的用户会同时去抢标,平均每秒大概有千人左右的并发,满标控制这块没有经过大的并发测试,上来之后就被打垮了,导致得结果是什么呢,1000万的标的,有可能到一千零几万满标,也有可能会九百多万就满标,也就说要不就是多了一些,要不就是少了一些,就满标了。
这就会很尴尬,因为借款用户就借款一千万整,那么多出来的钱不能给用户回退,因为用户好不容易才抢上了,无端退了用户也闹;少了也是问题,用户借款一千万,少了几十万也不行,如果缺的少了可以想办法找一些有钱的客户直接给买了,多了就必须重新放出来让用户投资,非常影响士气,这个问题困扰了我们有一段时间。
购买标的流程图,不知道大家是否能根据此图发现问题呢?
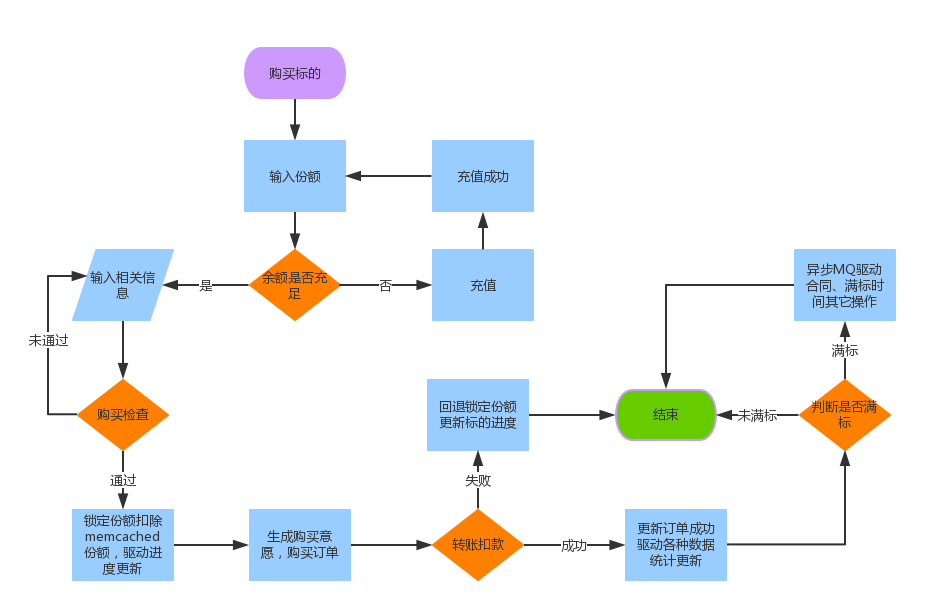
超募
为何会产生超募?在最早前的版本中没有使用乐观锁来控制,如果在最后购买的用户一单出现并发,就会出现超募,比如最后剩余30000份的购买份额,因为并发量特别大,可能同时会有十几个用户拿到了剩余30000份余额的可购买额度,有的买1000份、有的买上3000份、有的买上20000份都会驱动满标,所以最后导致了超募。
针对这个问题,主要是引入了memcached乐观锁的概念(底层主要是cas、gets两个命令),在发标的时候存入标的总份额,当用户购买的时候首先去锁定用户购买的份额,因为乐观锁的原因,如果同时有两个用户拿到份额的时候保证只有一个最后可以更新成功(锁定份额),(锁定份额)失败直接返回,这样就保证了在入口的时候就直接屏蔽了部分并发的请求。
少募
为何产生少募?少募是可能1000万的标的突然到980万就给满标了,这是因为在超募情况下我们完善了代码,用户一进来首先就是锁定购买份额,只有锁定购买份额才能进行下面的流程,如果锁定购买份额失败直接返回,这样虽然保证了在1000万份额在购买初期必须每一个用户只能锁定一份,但是在高并发的情况下,因为购买流程中有十几个分支,每一个分支失败就会退回锁定的份额,这样就会导致这样的现象,就是可能是并发一上来,马上就满标了,过了一会进度又回退回来了。
少募主要是因为分支失败回退导致的,一方面我们分析了容易导致回退热点,因为在用户抢标的时候会给用户实时的展示标的进度,在很早的版本中直接就是存入到一个标的进度表里面,并且采用了乐观锁,如果并发一高就频繁的更新失败导致回退,因此优化了标的进度这块,直接去掉了标的进度表,实时根据查询来展示标的进度(可以有延迟,有缓存);另一方面在回退份额的时候在次判断试下memcached的份额和标的的状态,如果份额不为零并且标的状态是满标,马上自动更新状态保证后续用户可以立即购买再次驱动满标。
做了以上的两种优化后,我们还遇到了其它的一些小问题,在不断的优化过程中,终于稳定下来;在后期版本中将考虑使用MQ队列或者redis队列来处理抢标更合理对用户也更公平一些。
重复派息
15年的某一天看到一个新闻说是陆金所的一个用户发现自己银行里面突然多了很多钱,没过多久又被扣走了,然后收到陆金所那边的解释,说是给用户还本派息的时候程序出现了问题导致还本派息两次,当他们程序员发现了此问题后紧急进行了处理,用户当然闹了呀,就上了新闻,当然陆金所通道能力确实比较强可以直接从用户卡里面扣,当大家都兴致勃勃的谈论这个话题的时候,我却有一股淡淡的忧伤,为什么呢?因为这个错误我们也犯过,具体说就是我搞的,大家可不知道当时的心里压力有多大!
事情是这样子的,我们使用的第三方支付的扣款接口不是特别的稳定,于是我们前期就对接了两种不通的扣款接口,平时前端投资的时候走一个接口,后端派息或者还本的时候走另外的一个接口,在初期的时候扣款接口不稳定,因此在给用户跑批的时候经常会有个别用户失败,需要手动给失败的用户二次派息。做为一个有志向的程序员当然觉得这种方式是低效的,于是将程序改造了一下,在后端派息的时候当第一种扣款失败的时候,自动再次调用第二种扣款接口进行扣款,当时想着这种方式挺好的,各个环境测试也没有问题,上线之后监控过一段时间也运行稳定。
当我感觉一切都很美妙的时候,事故就来了,突然有一天客服反馈说有的用户说自己收到的利息感觉不对,好像是多了(真的是太感谢这个用户了),我登录后台看了一下派息的流水复核了一遍,果然利息被重复派了,一股冷水从头而下,把当天所有的用户派息记录和到期记录都进行了检查,影响了70多个用户,导致多派息了6万多元,幸亏只是派息出了问题,如果是到期的话金额会翻N倍,其中70多个人里面有几个进行了体现、几个进行了再次投资,绝大部分用户在我们发现的时候还不知情,金额也没有动。
怎么处理呢,当然不能直接就动用户的钱了,给每个重复派息的用户打电话,说明原因赠送小礼物,请求谅解后我们把重复派过的利息再次调回来。大部分用户进行了核对之后都还是比较配合的,但是肯定有一些用户不干了,当然也不能怪客户,都是我的原因,有的客户需要上门赔礼道歉,有的客户需要公司出具证明材料,我们的老板亲自给客户打了N个电话被客户骂了N遍,我心里压力可想而知,其中有一个客户特别难缠,各种威胁说既然到了我的账户里面肯定是我的,你们的失误不应该让他来承担,折腾了很久,还是不能怪客户。可能会说有的互联网公司经常出现这种问题后就送给客户了,哎,我们是小公司呀!这个噱头玩不起。
到底是什么原因呢,事后进行了复盘也给领导做了汇报,平时都是首先进行派息的定时任务,过一个小时之后进行到期的定时任务,当天的派息标的比较多,跑了一个半小时,就导致了派息和到期的两个定时任务同时进行,转账有了并发,第三方支付的接口不稳定给我们返回的失败,其实有的是成功的,就导致了我们进行了二次的扣款尝试引发了此问题。这个事情给我带来了非常大的教训,对于金融扣款的这种事情一定需要谨慎,那怕付款引发报警之后再人工处理,也不能盲目重试可能引发雪崩效应。
杂七杂八
还有就是其它一些零碎的问题了,记的有一次对用户的登录过程进行优化,导致有一块判断少了一个括号结果用户在那两个小时内,只要输入账户,任意密码就可以登录了,幸好及时发现这个问题,正是这个问题才导致了我们正式确立了规范的上线流程,为以后的上线制度建定了基础。
还有一次我们在模拟用户投资一种标的时候,留了一个入口通过http就可以调用,测试也没有问题,有一天正好给领导演示呢,就在次用http请求的方式在浏览器执行了一下,前端就会看到自动投标的过程,因为生产的数据有点多,投标的过程有点长,我们为了加快进度,找了好几个人同时来执行这http请求,导致最后出现了问题,最后发现写测试脚本的这个同事根本就没有考虑并发的情况,才导致出现了问题。
也做了很多的活动,记得做一个网贷之家的一个活动的时候,活动上线比较紧张,我们团队曾经连续工作超过30个小时(一天一夜再一天),当天晚上我2点左右写完程序,测试从2两点测试到早上9点,最终确认没有任何问题,才进行投产。半夜公司没有暖气,我们实在冻的不行了,就在办公室跑步,从这头跑到那头,第二天上线之后,又害怕出现问题,监控了一天,确认没有任何问题,才到下午正常下班回家,那时候真是激情满满呀。
说到做活动肯定少不了羊毛党,说哪一家互金公司没有遇到过羊毛党那很少见,而且现在的羊毛党规模简直逆天了,我们用户里面就有一个羊毛党在两三天之内邀请了六七千位用户,如果说邀请一个用户送1元,那这个用户就可以搞几千块一次,而且有很多专业的网站、QQ群、微信公共账号都是他们的聚集地,哪天哪个平台有活动门清,他们写的淘羊毛操作手册有时候比我们官网的帮助文档还清晰,所以做活动的时候要考虑特别周全,各种限制,有封顶、有预案、讲诚信,只要是符合我们活动规则的坚决按照流程走。
还有一个有趣的事情,app推送,一次我在公交车上就看到xx盒子app弹出hhhhh的推送,这个事情我们也搞过,因为在调试的时候生产和测试就差了一个参数,有时候开发人员不注意就把生产参数部署到uat环境了,测试一发送就跑到生产了,这方面只能严格按照流程管理来防止。
其实还很多问题:mongodb集群和mysql的同步出现的一些状况、后台大量数据查询下的sql优化、golang使用mapreduce碰到的问题… 限于篇幅这里就不一一清晰的描述了。
其实每次的出现问题都是对团队一次非常好的锻炼机会,通过发现问题,定位问题,解决问题,再次回过头来反思这些问题;重新梳理整个环节, 举一反三避免下次再次出现类似的问题。正是因为经历这些种种的困难、考验才让团队变的更强大更稳定,也更体现了流程的重要性,更是避免再次发生类似问题。
总结
古人有云,胸有惊雷而面如平湖者,可拜上将军。在互联网行业对大牛的要求也同如此,特别是技术的负责人,在面对生产事故的时候,一定首先是安抚同事,静下心来找到问题本质再去解决,而不是不断去施加压力催促解决,重压之下很多心里承受能力稍弱的队友,更加慌乱而不利于解决问题或者引发二次事故。
在看淘宝双十一视频中,有一段特别受到感触,在双十一初期,虽然技术团队做了很多的准备,但是在零点过后流量瞬间涌入,服务被打垮,部分用户投诉刷新不出网页,紧接着隔壁同事也都反馈网站打不开,在大家都在慌乱中,xx一拍桌子大喊一声,大家都别动,三分钟之后再说,过了几分钟之后服务慢慢部分恢复了正常。后来回忆说,当时虽然服务瘫痪,但是监控还是有部分得业务成功,说明系统并没有被压垮,而此时的任何操作都有可能引发更大的问题,从此之后此人一战成名,成为阿里大将。
互联网平台发展大抵都会经历三个阶段:
-
1、上线初期,此阶段问题最为繁多,生产事故不断,系统快速迭代优化。有人说为什么不测试到完全没有问题再投产吗?说实话在互联网行业这个很难,小公司很难做到生产环境和测试环境一致,成本太高;时间紧迫,一般都是很短的时间内要求上线,上线之后在快速迭代。另外互联网本就是一个快速试错的行业,错过半年时间可能风口早过;
-
2、发展期,此阶段主要业务模式已经得到验证,系统出现问题的频繁度较少,低级错误减少,但此时是用户量和交易量不断爆发的时候,对系统性能、高并发的要求又上来了,所以此时出现的问题大多都是性能的问题;
-
3、成熟期,发展期过后系统相对比较平稳,用户量和交易量都已经慢慢稳定下来,生产问题越来越少,出现问题几乎都是细小的bug,这个阶段也是公司最忽略技术的阶段,恰好我们公司就处于这个阶段,在这个阶段就需要静下心来,组织架构升级,补齐在初期和发展期所欠的技术债务,做好公司在升下一个量级的技术准备。
所有的这些问题几乎都集中在14年底到15年初的这个阶段,15年后半年开始到现在平台慢慢稳定了下来,到现在几乎没有再出现过类似的问题,也因为几乎都是两年前的事情,有很多记的不是特别清楚了,写的比较粗糙望见谅。
作者:纯洁的微笑
出处:www.ityouknow.com
版权归作者所有,转载请注明出处

微信扫描二维码,关注一个有故事的程序员
(点击了解: 关于程序员的专属导航!)
Post Directory